canirun.ai rappresenta una piattaforma che permette di valutare la fattibilità di esecuzione locale di modelli di intelligenza artificiale, analizzando l’hardware del computer e fornendo una stima delle prestazioni per i principali modelli AI. l’obiettivo è offrire una guida pratica per comprendere quali modelli è possibile far girare in locale senza rely sul cloud, tenendo conto di risorse come GPU, VRAM, RAM e core disponibili.
canirun.ai: funzionamento e obiettivo
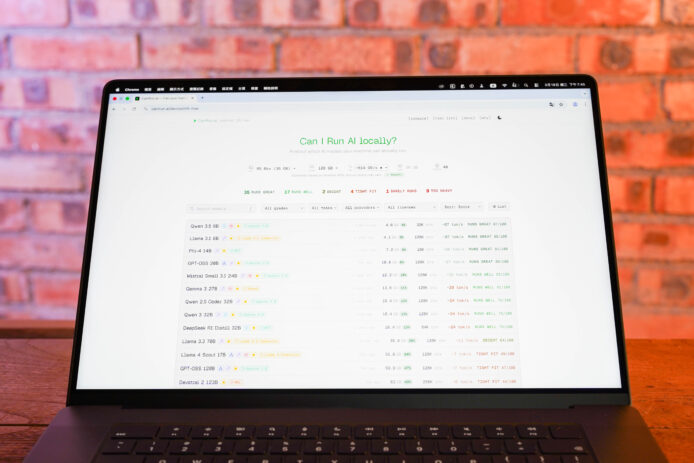
la soluzione sfrutta le tecnologie web per leggere direttamente la configurazione hardware del dispositivo tramite WebGPU. in questo modo emergono dati su GPU, VRAM, bandwidth, RAM e core, permettendo di stimare in tempo reale la compatibilità con modelli AI di diversa complessità. il sistema è progettato per offrire indicazioni affidabili senza necessità di eseguire simulazioni manuali complesse, facilitando la scelta di modelli adatti alle risorse disponibili.
come opera la diagnosi in tempo reale
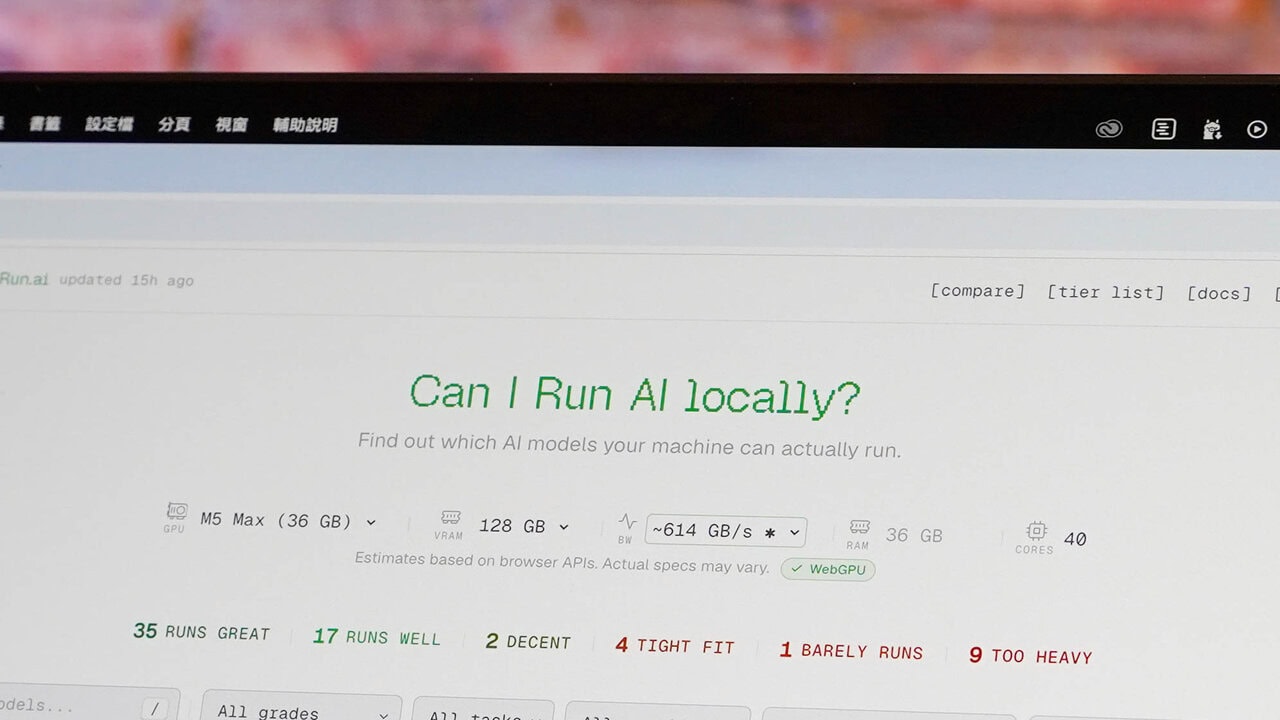
all’accesso alla pagina, la piattaforma esegue automaticamente una scansione della configurazione hardware. si segnala l’utilizzo preferenziale di Chrome o Edge per garantire un rilevamento più accurato, poiché Firefox e Safari possono limitare l’accesso a dati di sistema per motivi di sicurezza. la diagnosi iniziale riporta informazioni su GPU, VRAM, RAM e cores.
uso pratico: guida all’uso
una volta aperto il sito, la scansione avviene in modo automatico e immediato. per Mac, i dati mostrati possono prevedere limiti legati al rilevamento di memoria; in questi casi è possibile intervenire manualmente sui valori di VRAM per simulare potenziamenti reali dell’hardware. nelle prove eseguite si ritiene utile impostare la memoria virtuale (VRAM) a una percentuale vicina al 70%–80% della RAM totale, così da ottenere una previsione più vicina al comportamento di un’applicazione nativa.
interpretazione dei risultati
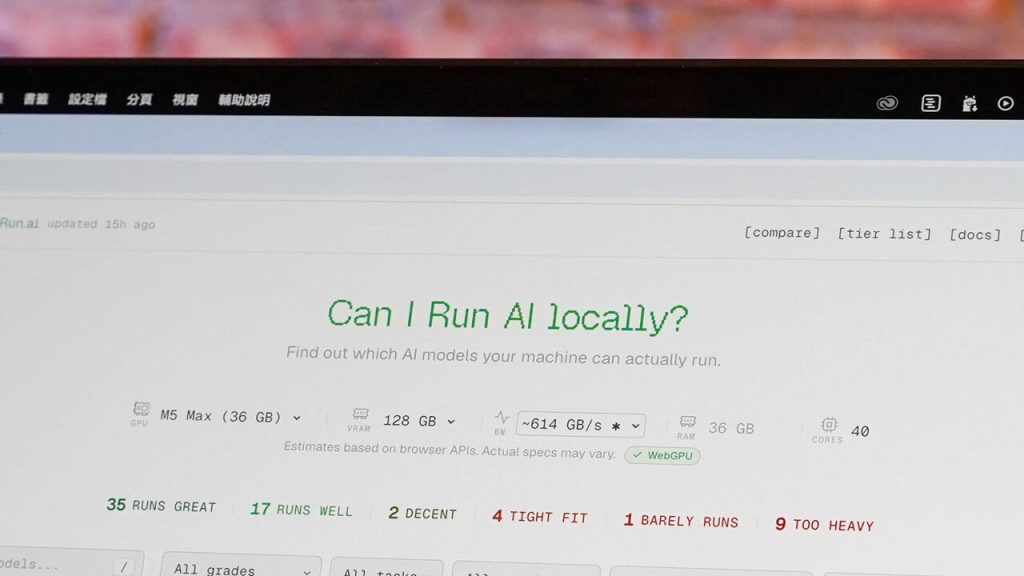
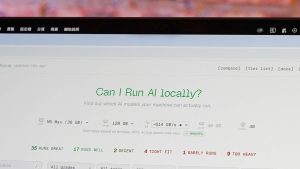
nelle verifiche condotte su un MacBook Pro M5 Max 128 GB di RAM, la piattaforma ha contrassegnato 35 modelli come “Runs Great” e 10 modelli come “Too Heavy” (valutazioni previsionali). l’analisi dimostra come, a seconda della configurazione, alcune soluzioni risultino adeguate all’esecuzione locale, altre richiedano potenziamenti o una gestione differenziata dei modelli.
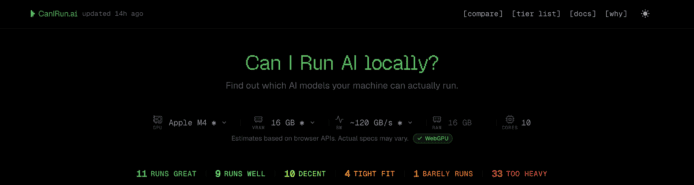
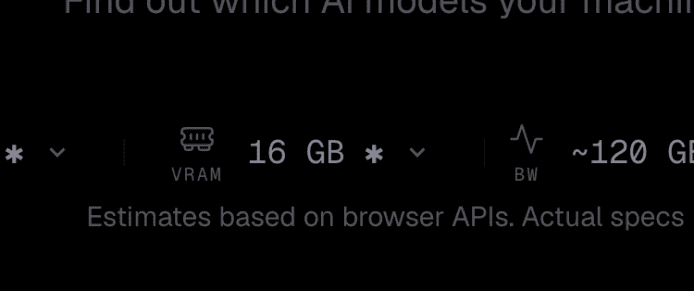
ipotesi su iMac M4 e test di potenza
per l’iMac M4 con 24 GB di RAM, configurando manualmente la VRAM a 18 GB, si ottimizza la corrispondenza tra valutazione e realtà: modelli leggeri come Llama 3.2 1B raggiungono un valore di 156 tok/s, mentre modelli di livello medio come Llama 3.1 8B si mantengono attorno a 19 tok/s, offrendo prestazioni adeguate per riassunti o scrittura creativa. complessivamente, l’analisi su 24 GB di RAM evidenzia una presenza significativa di modelli capaci di operare in modo fluido, con una parte di modelli più gravosi che richiede ulteriori risorse o configurazioni diverse.
funzionalità avanzate: confronto GPU
tra le funzionalità avanzate spicca la confrontazione tra GPU integrata, utile per valutare l’impatto di un upgrade. è possibile confrontare l’attuale dispositivo con una GPU di fascia alta, come RTX 5090, per stimare la velocità di generazione (-tok/s-). nel confronto tra Mac M4 e RTX 5090, emergono dati significativi: per modelli molto leggeri come Qwen 3.5 0.8B, l’iMac M4 offre circa 156 tok/s, mentre la RTX 5090 raggiunge circa 2509 tok/s, con un gap di circa 16x. per modelli da 9B, M4 si attesta intorno a 17 tok/s, contro circa 273 tok/s della RTX 5090.
un altro confronto riguarda le prestazioni su modelli locali già testati: nel contesto di Qwen 3.5 0.8B e altre configurazioni, la piattaforma evidenzia la capacità di generare contenuti rapidamente in ambienti hardware avanzati, offrendo una base di riferimento utile per valutare possibili aggiornamenti o la scelta di soluzioni alternate di calcolo locale.
limiti e indicazioni pratiche
nonostante l’utilità di canirun.ai per i neofiti, restano alcune limitazioni: non tutte le schede hardware sono completamente coperte dall’elenco dei modelli; in certi casi, soprattutto su computer con memoria molto ampia, la rilevazione automatica può segnalare valori inferiori rispetto alle prestazioni reali di un’applicazione nativa. in tali scenari, l’uso della funzione di input manuale per VRAM permette di ottenere una valutazione più accurata delle potenzialità disponibili sul sistema.







{kind=link}
Lascia un commento