introduzione sintetica il presente testo analizza l’implementazione di Gemini per l’automazione dello schermo su Android, evidenziando funzionamento, vantaggi, criticità e temi di privacy. l’approccio descrive una gestione di azioni su app e servizi senza intervento manuale, offrendo nuove possibilità di multitasking e accessibilità nell’uso quotidiano.
gemini screen automation su android
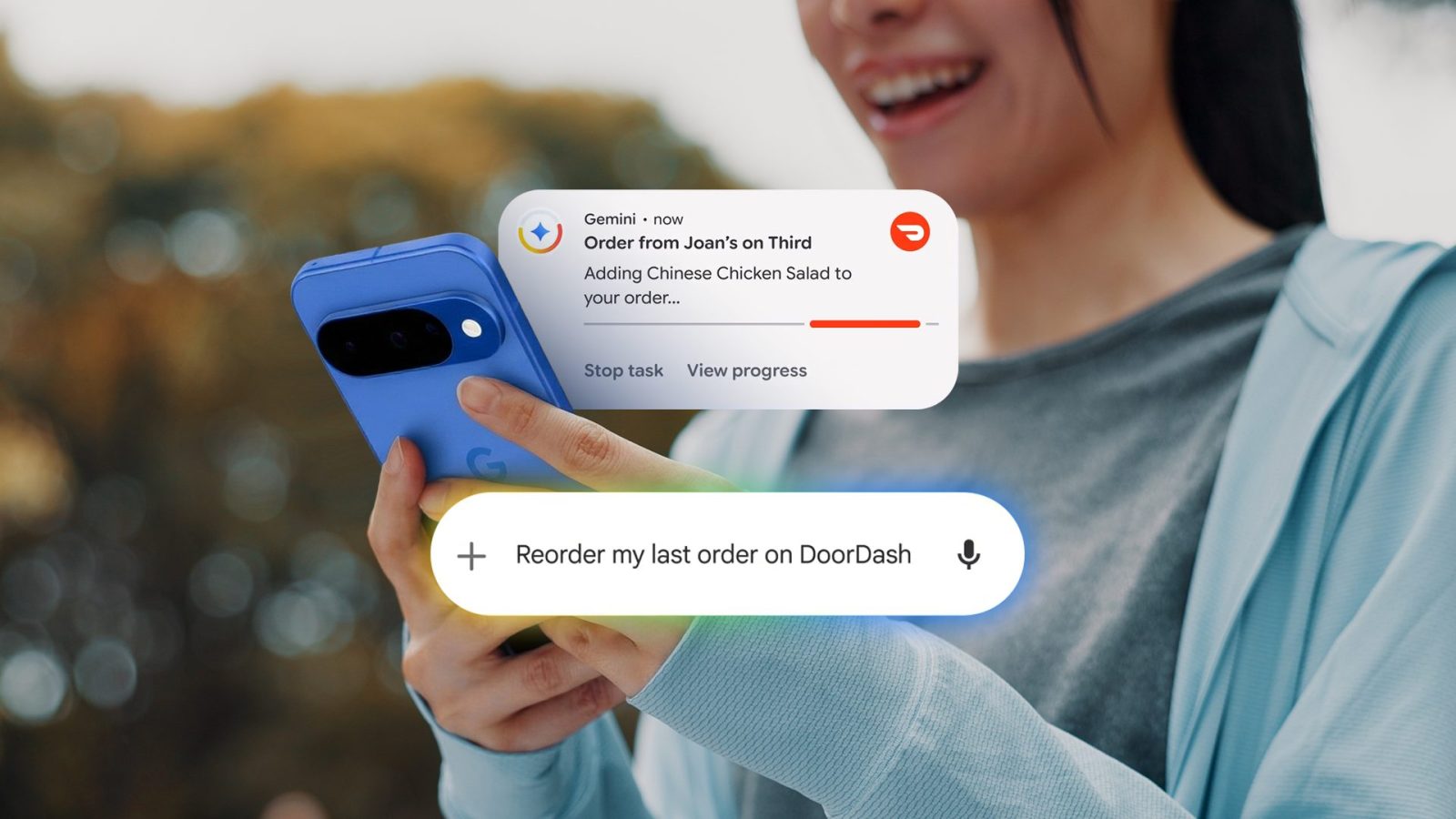
gemini introduce un modo di interazione che va oltre le routine tradizionali: la lettura dello schermo identifica elementi come campi di testo, menu e barre di ricerca e interagisce con essi in tempo reale, come farebbe un utente. si possono inviare comandi vocali per azioni ricorrenti, ad esempio “ordinare la pizza abituale” o “prenotare un Uber per l’aeroporto”, e l’assistente gestisce l’intero flusso fino al checkout. l’esecuzione avviene senza prendere possesso del dispositivo: tutto resta in una sandbox che opera in background.
meccanismo di lettura dello schermo e interazione in tempo reale
rispetto agli assistenti tradizionali che operano entro limiti API, gemini offre un approccio diverso: legge ciò che appare sul display, riconosce elementi dell’interfaccia e agisce direttamente sugli elementi rilevati. questa capacità apre scenari di automazione più naturali e contestualizzati, senza richiedere integrazioni complesse.
esecuzione di comandi vocali e azioni
comandi come “ordina la tua pizza venerdì sera” o “chiama un taxi” vengono eseguiti dall’assistente, che aggiunge elementi al carrello, procede al checkout e conclude l’operazione. l’interazione avviene in tempo reale, completando passaggi successivi senza richiedere intervento manuale.
sicurezza e sandbox
l’esecuzione resta in sandbox, operando in background senza controllare l’intero dispositivo. questa architettura mira a mantenere la privacy dell’utente mentre si limita l’ingerenza nel sistema operativo.
vantaggi e sfide dell’automazione
l’uso di automation mirata consente risparmio di tempo e miglioramenti nell’accessibilità, supportando soprattutto chi necessita di multitasking e supporto motorio. la capacità di compiere azioni complesse in modo fluido rappresenta un salto significativo nell’interazione con le app. Emergono criticità: le interfacce moderne non sono statiche e modifiche improvvise ai layout, come lo spostamento di pulsanti o etichette, possono compromettere l’operatività dell’agente.
altre limitazioni sorgono quando l’agente deve gestire finestre emergenti, banner informativi e richieste di consenso. non sempre è possibile evitare interruzioni; in caso di problemi, è disponibile un intervento manuale per ripristinare la situazione e far riprendere l’uso automatizzato. in definitiva, resta ancora una fase in cui la manualità può risultare più efficiente in specifici contesti, ma la prospettiva è di un effettivo incremento della produttività e della facilità d’uso.
un tema cruciale riguarda l’impatto sugli annunci pubblicitari: se l’agente lavora in background, potrebbe non intercettare contenuti sponsorizzati o offerte commerciali e ciò potrebbe influire sui modelli di monetizzazione delle app. la dinamica tra avanzamenti tecnologici e meccanismi di revenue richiede attenzione, con scenari ancora da definire.
l’uso di infrastruttura agenziale solleva domande anche sull’evoluzione futura delle interfacce: potrebbe essere necessario sviluppare UI non dipendenti dall’interazione umana o introdurre soluzioni che incentivino l’interazione con gli agenti anziché con l’interfaccia visuale tradizionale.
privacy e sicurezza in gemini
per utilizzare la modalità agentica, è necessario concedere accesso profondo al dispositivo. google propone di isolare l’agente in una finestra virtuale, mantenendo l’ambiente in sandbox e limitando la visibilità dell’agente al contesto della sessione corrente.
I dati generati durante la sessione (ordini, spostamenti, spese) possono essere trasmessi ai server di google, aprendo la possibilità di creare profili più dettagliati della daily life. questa dinamica richiede una valutazione attenta di bilanciamento tra utilità e tutela della privacy.
l’isolamento tecnico evita che l’agente controlli l’intero dispositivo, ma la raccolta di dati della sessione resta un aspetto cruciale da monitorare per chi pone l’accento sulla riservatezza delle informazioni personali.
disponibilità e modelli di prezzo
la funzione beta è disponibile al momento su dispositivi di fascia alta, come la serie pixel 10 e la serie galaxy s26, con disponibilità limitata agli stati Uniti e alla Corea del Sud. è presente un modello a livelli che impone quote giornaliere di richieste per l’automazione dello schermo.
piani e relative quote di utilizzo:
- Gemini Basic (senza Google AI): 5 richieste al giorno
- Google AI Plus: 12 richieste al giorno
- Google AI Pro: 20 richieste al giorno
- Google AI Ultra: 120 richieste al giorno
l’introduzione di una tariffazione per funzionalità avanzate, simile a quanto visto con altre soluzioni, segnala una direzione commerciale che potrebbe evolversi con nuove feature e permessi a seconda della regione e del livello di abbonamento.
non perfetto yet, ma non passibile di ignoramento
l’automation agentico di gemini si trova in una fase intermedia: il sistema richiede ancora adattamenti a interfacce progettate per mani e occhi umani, e possono presentarsi prompt confusi o situazioni in cui è preferibile operare manualmente. questa condizione non deve essere interpretata come un inutile esperimento, bensì come l’inizio di qualcosa di molto più ampio. in futuro, potrebbe accadere che le app riducano la dipendenza dalla layer visiva e interagiscano direttamente con gli agenti, cambiando radicalmente l’esperienza utente. per ora, osservare gemini navigare tra software esistenti offre una prospettiva concreta su ciò che potrebbe arrivare.







{kind=link}
Lascia un commento