
questa presentazione illustra la roadmap a quattro generazioni di architetture GPU formulate da una nota azienda cinese specializzata, orientata a offrire prestazioni elevate, prevedibilità operativa e sostenibilità energetica. si evidenzia un obiettivo ambizioso di superare l’attuale riferimento di mercato e un percorso di adozione con oltre 300 clienti e più di 1.000 implementazioni completate, a conferma della rapida diffusione nel contesto AI e HPC.
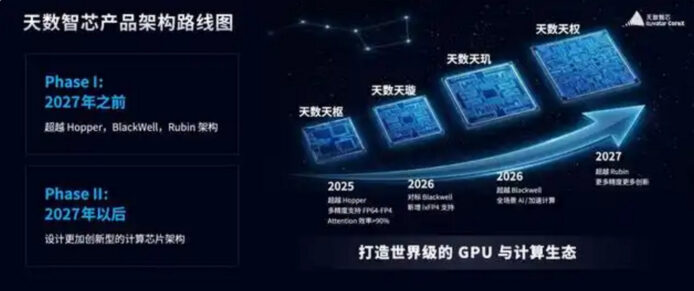
tian shu zhi xin: quarta generazione di architetture per superare nvidia rubin
una roadmap dettagliata indica l’evoluzione prevista: nel 2025 è previsto il lancio della architettura 天樞, con l’obiettivo di superare la serie Hopper (H200); nel 2026 arriveranno 天璇 e 天璣, con l’obiettivo di superare rispettivamente Blackwell (B200) e, nello stesso periodo, Blackwell stesso; nel 2027 si punta a 天權, con l’intento di superare Rubin. l’azienda intende proseguire oltre il 2027 con progetti di architetture di calcolo all’avanguardia, dedicate a scenari complessi. queste previsioni mirano a offrire ai clienti un tco (costo totale di proprietà) ridotto grazie a innovazioni progettuali che favoriscono l’efficienza e la gestione di applicazioni eterogenee.
l’esecuzione di design avanzati si concentra sull’ottimizzazione delle prestazioni per contesti complessi, con una visione orientata a fornire capacità di calcolo mirate al time-to-solution e a una gestione energetica più efficiente. in questa prospettiva, l’azienda intende rendere le soluzioni sempre più competitive nel panorama globale.
天樞架構: innovazioni chiave
l’architettura 天樞 introduce diverse innovazioni centrali, che si traducono in un incremento dell’efficienza e nell’abbattimento dei consumi. tra le principali:
- TPC BroadCast (calcolo di broadcast): progettato per ridurre le visite di memoria ripetute tramite la diffusione upstream dei dati, con conseguente incremento della larghezza di banda effettiva e minori consumi energetici.
- Instruction Co-Exec (’elaborazione multi-istruzione): permette l’esecuzione parallela di differenti tipi di istruzioni, aumentando la capacità di gestire compiti complessi.
- Dynamic Warp Scheduling (pianificazione dinamica dei gruppi di thread): evita la contesa di risorse mediante una schedulazione flessibile, migliorando l’efficienza dell’uso delle risorse di calcolo.
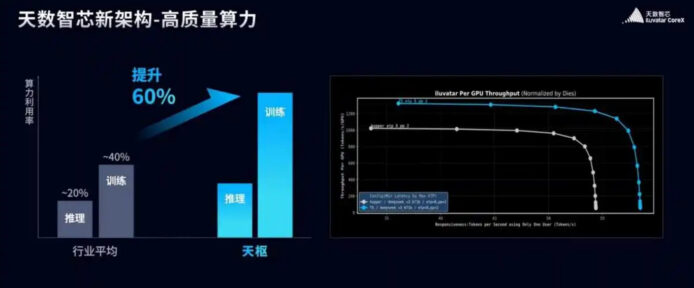
4a generazione: caratteristiche chiave
le innovazioni di 天樞 e delle architetture successive si concentrano su una gamma di capacità, dalla precisione scientifica all’intelligenza artificiale. in particolare, l’attenzione al meccanismo di AI consente un’effettiva utilità del calcolo superiore al 90% in scenari di esecuzione di modelli avanzati. inoltre, 天璇 introduce estensioni di precisione ixFP4; 天璣 espande la copertura per scenari AI e accelerazione; 天權 integra ulteriori opzioni di precisione e nuove innovazioni progettuali. complessivamente, tali sviluppi proiettano un incremento di efficienza rispetto agli standard di mercato di circa il 60%, con prestazioni superiori per applicazioni come DeepSeek V3 rispetto alle architetture predecessor di circa il 20% in media.
sostegno istituzionale
in occasione della presentazione, un accademico di rilievo ha sottolineato l’esigenza di coniugare quantità e qualità dell’AI, promuovendo una stretta integrazione tra software e hardware per abilitare l’uso di soluzioni sia in data center sia in edge computing, con una visione di ecosistema aperto e sostenibile. l’intervento ha evidenziato l’importanza di un approccio basato su principi di innovazione autonoma e collaborazione strategica per guidare lo sviluppo di soluzioni GPU domestiche.
una parte di leadership aziendale ha rimarcato la necessità di consolidare un ecosistema autonomo di GPU generiche, orientato a una crescita a lungo termine tramite alleanze aperte e una pianificazione orientata al futuro della computazione.
- 劉韻潔 — accademico della Chinese Academy of Engineering
- 盖鲁江 — presidente e amministratore delegato di 天數智芯









{kind=link}
Lascia un commento