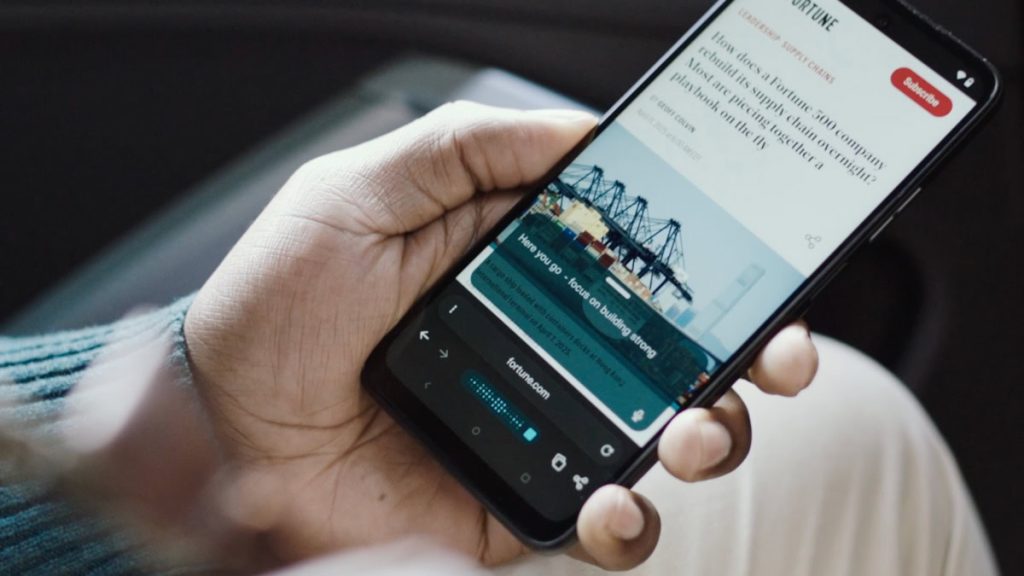
L’intelligenza artificiale sta rivoluzionando il modo di reperire informazioni, permettendo di attingere simultaneamente a molteplici fonti e sintetizzare i dati in maniera rapida ed efficiente. Questa capacità rappresenta un vantaggio considerevole per gli utenti, ma solleva questioni legali rilevanti per gli editori che vedono i propri contenuti utilizzati senza autorizzazione.
cause legali contro perplexity per violazione del copyright
Recentemente, il Chicago Tribune ha avviato una causa giudiziaria contro Perplexity, un’azienda che sviluppa sistemi di intelligenza artificiale, accusandola di violazione del diritto d’autore. Secondo quanto riportato dagli avvocati del quotidiano, Perplexity avrebbe estratto e riprodotto fedelmente contenuti pubblicati dal Chicago Tribune senza ottenere alcun permesso.
Nel dettaglio, a metà ottobre gli avvocati del giornale avevano contattato Perplexity per chiarire se la società utilizzasse i loro articoli come materiale di addestramento dei modelli AI. La risposta dell’azienda è stata negativa, ammettendo però la possibilità di fornire agli utenti riassunti fattuali non testuali degli articoli.
Tale difesa è stata contestata dal Chicago Tribune, che sostiene invece l’estrazione letterale dei testi dalle proprie pubblicazioni. Al centro della disputa vi è la tecnologia denominata retrieval augmented generation (RAG), impiegata da Perplexity per offrire risposte basate su fonti verificate e aggiornate anziché su dati obsoleti o generati arbitrariamente.
Inoltre, viene evidenziato come il browser Comet sviluppato da Perplexity aggiri le barriere paywall presenti sui siti web per mostrare ai lettori sintesi dettagliate degli articoli protetti da abbonamento.
precedenti cause legali contro aziende AI
I procedimenti legali simili non rappresentano un caso isolato nel settore dell’intelligenza artificiale. Data la necessità di enormi quantità di dati per addestrare modelli performanti, molte piattaforme si rivolgono al web come principale fonte informativa. Tale pratica però incontra resistenze significative da parte degli editori digitali.
I costi sostenuti dalle aziende editoriali – tra cui ricerca giornalistica, stipendi del personale e infrastrutture tecnologiche – sono elevati. L’utilizzo non autorizzato dei loro contenuti da parte delle AI rischia di ridurre drasticamente il traffico verso i siti originali e quindi le entrate generate dalla pubblicità o dagli abbonamenti.
Esempi recenti includono:
- Perplexity citata in giudizio da Reddit con accuse analoghe relative allo scraping dei dati;
- OpenAI oggetto di causa dal New York Times, riguardante l’uso improprio delle conversazioni generate dall’utente;
- Editori uniti contro Google AI Overviews, considerati responsabili della diminuzione del traffico verso i portali editoriali tradizionali.








{kind=link}
Lascia un commento